
Demystifying Regular Expressions aka RegEx
Learn basics of regular expressions with examples


Regex is one of the most undervalued concepts of programming that can do wonders if used properly. In this blog, we'll be discussing what a regex is and its most common use cases. We'll also cover the most commonly used regular expressions with examples and learn how to write a regex. I have used regexr online editor. Other online editors like regex101 can also be used to test the regex.
 Credits: xkcd.com
Credits: xkcd.com
What is a regex?
A regular expression is a sequence of characters used for parsing and manipulating strings.
Regular expressions are patterns used to match character combinations in strings. For example: /Cat/, will look for Cat pattern and will return the first match that is encountered.
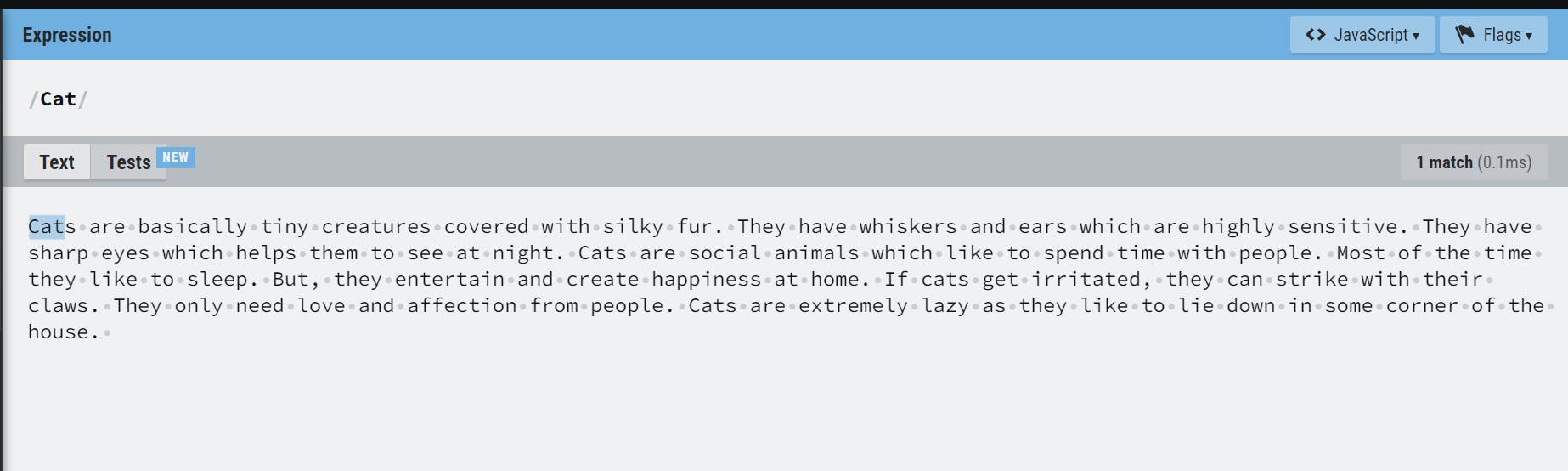
As shown in the above example, every pattern to be matched is wrapped inside two forward slashes (/).
Uses of regex
Regex is often used to define and search for patterns we are looking for in a big chunk of data/file. Web developers commonly use it for input field validations like email pattern matching, password pattern or strength check, checking the format of debit/credit card number entered, etc. Its use case is not only limited to web developers. Regular expressions play a very important role in the field of cyber security, penetration testing, data scrapping and network administration.
By now you must have understood that regex is not limited to any particular programming language and field. Most of the languages have regex as their default property while some require some third-party packages to be installed.
Understanding regex
A regex typically has three main parts - Opening and closing /, the pattern and the flag. We'll explore all, as we proceed.
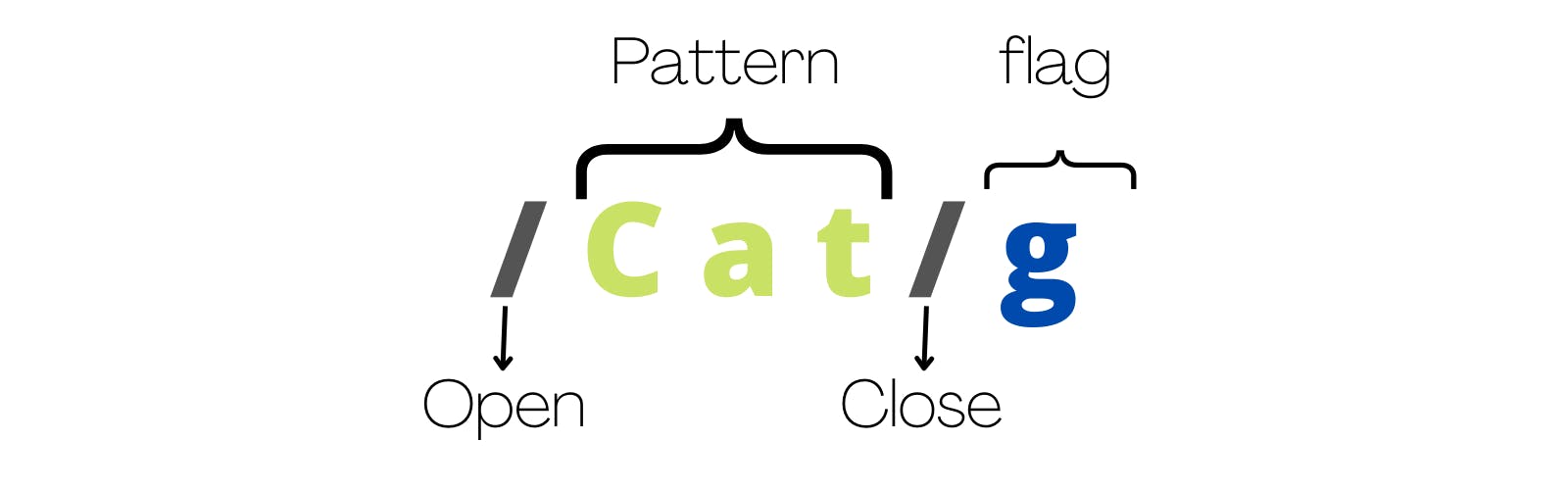
Flags
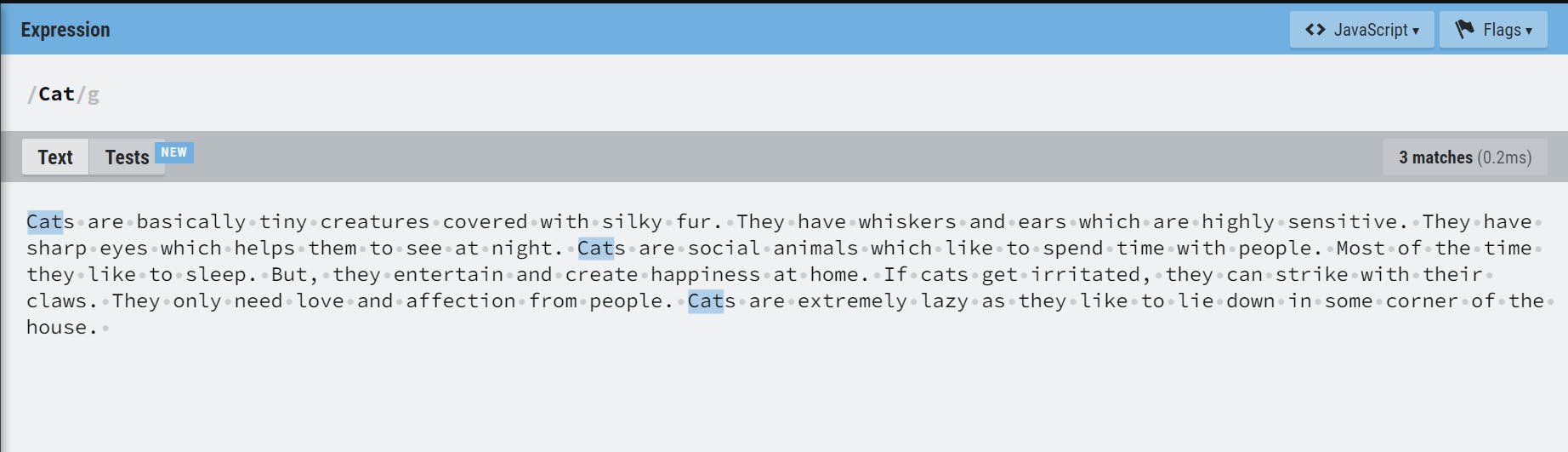
g(global)- returns all the matching cases
- Example:
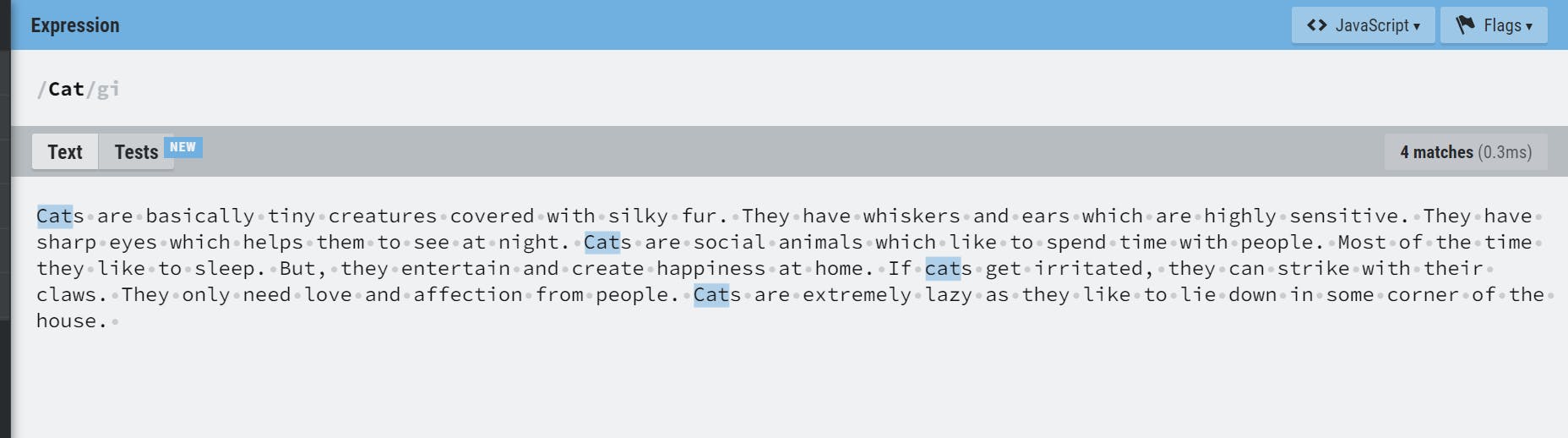
i(ignore case)- used for case-insensitive search
- Example:
m(multiline)- When the multiline flag is enabled, beginning and end anchors (^ and $) will match the start and end of a line, instead of the start and end of the whole string.
Example:
Without
mflag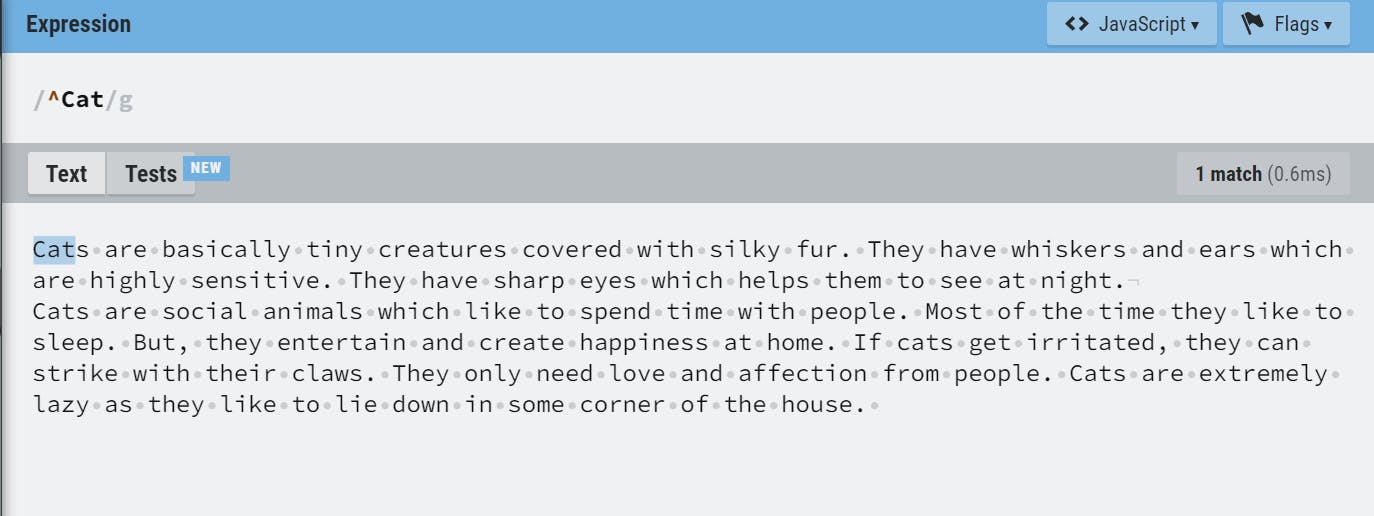 With
With mflag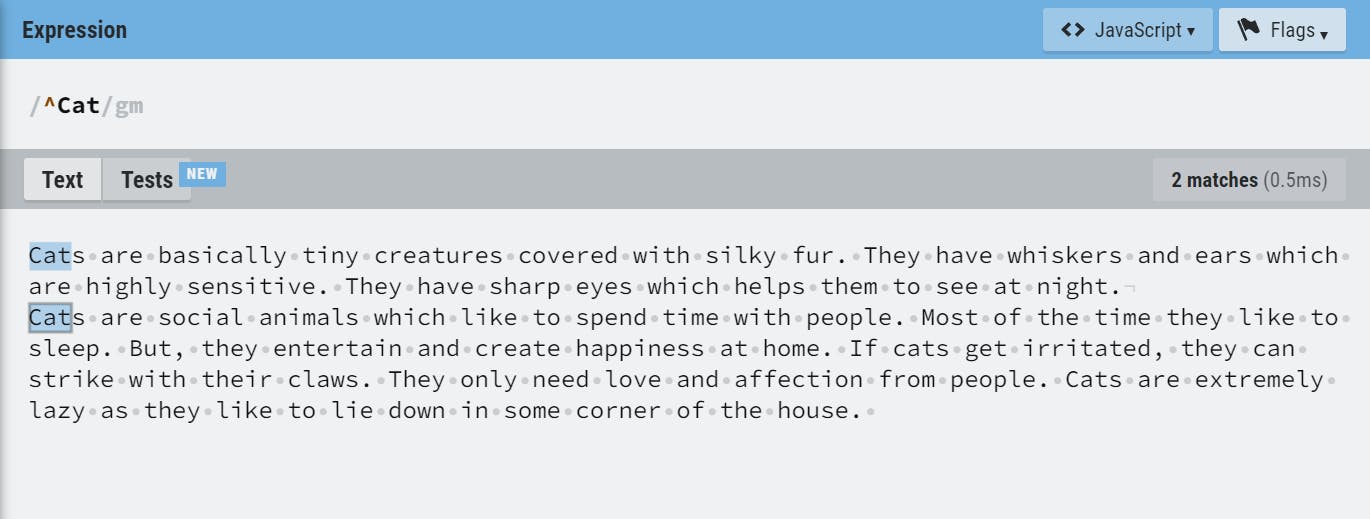
Apart from these we also have u(unicode), s(single line) and y(sticky) flags.
Wildcard Character( . )
It is used to match anything except line breaks. In this example, the. will look for the followed by any character
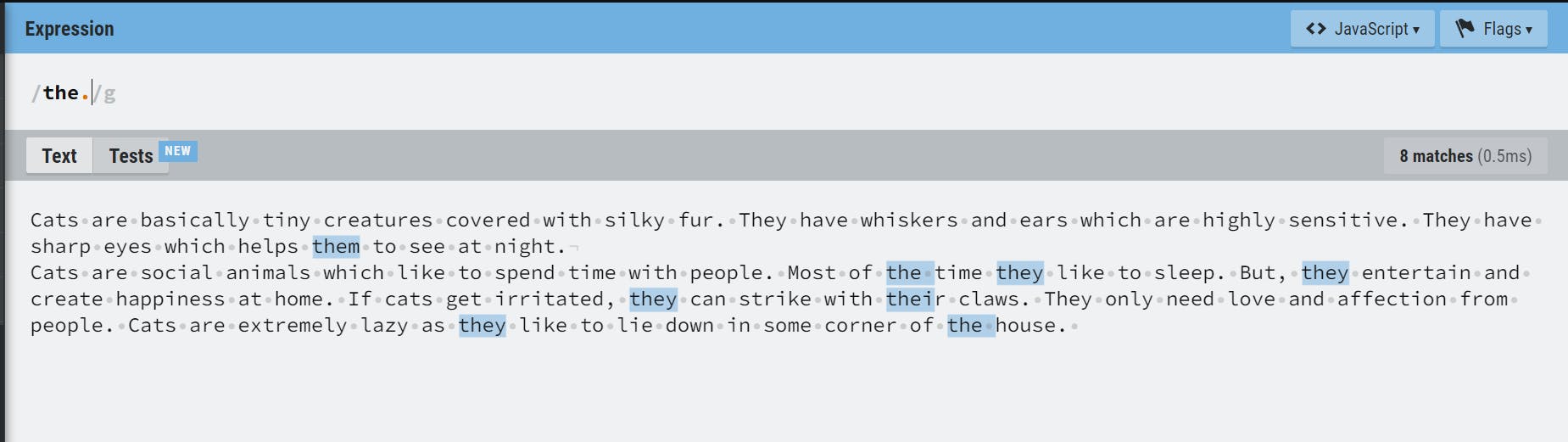
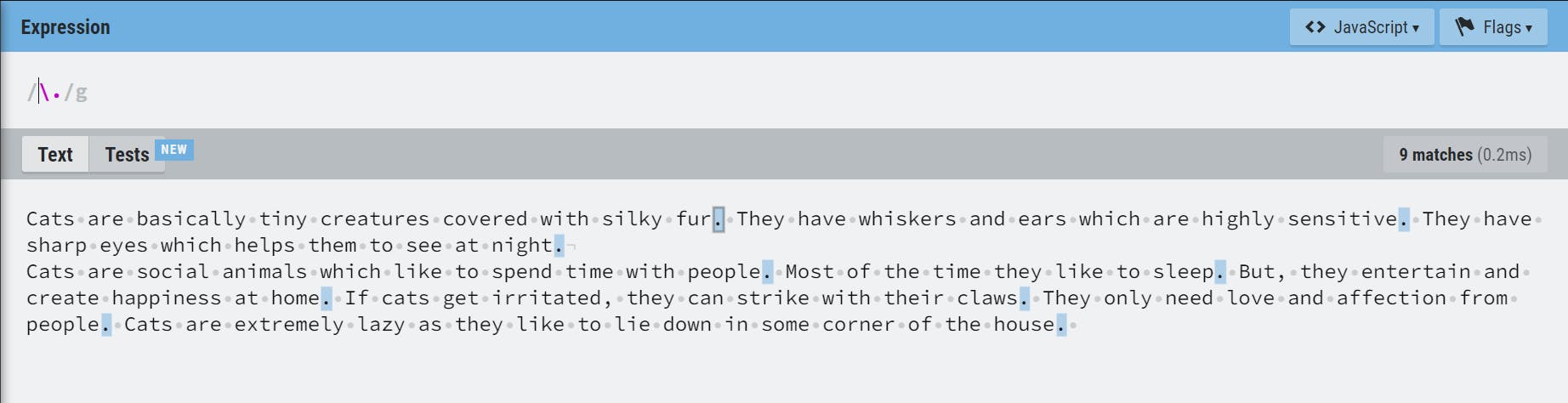
Escape Character( \ )
It is used for special characters which have a special meaning in a regex. In this example, \. will look for all the . in the given string
Example:
Character sets( [] )
Character sets are an important part of regex. It matches a single character in the mentioned pattern.
In this example, the[my] will look for the followed by either m or y.
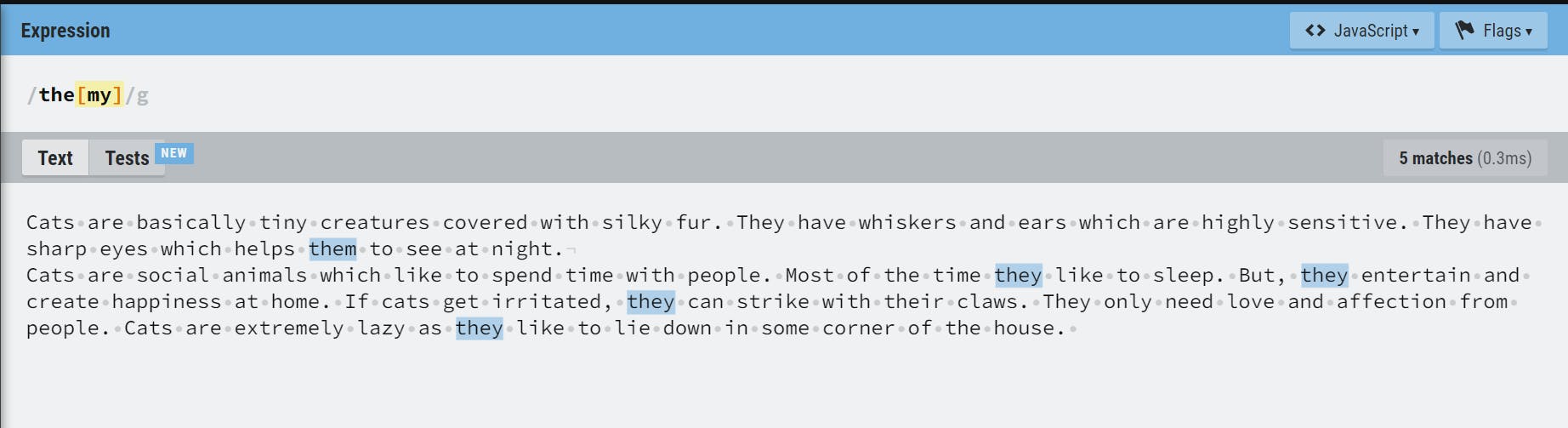
Note:
[.]matches for.unlike the case when it is not in-between character sets.-inside the character sets denotes range. Outside the character sets it behaves like a normal hyphen i.e. it does not have any special meaning outside character sets.[0-9],[A-Z],[a-z]are some examples of range.[20-35]does not check for the range 20 to 35. Instead, it will look for2or range0-3or5in the string.
Negation or negative character( ^ )
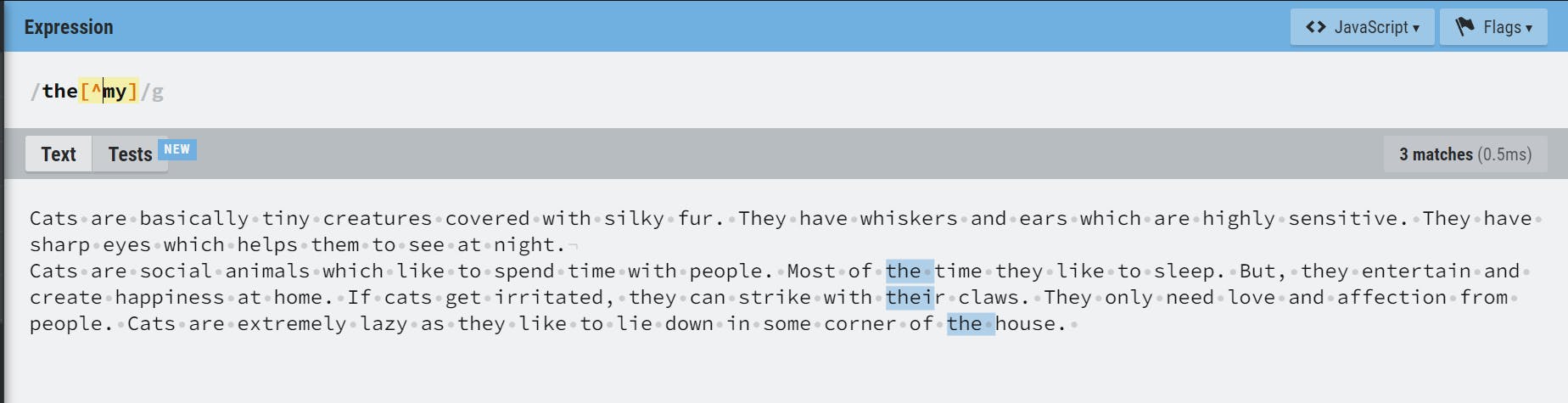
It is similar to ! in many languages. It will look for a pattern not equal to the mentioned pattern. It works inside character sets. Outside them, it has a different special meaning. In the below example, the[^my] will look for the not followed by m or y.
Anchors( ^, $ )
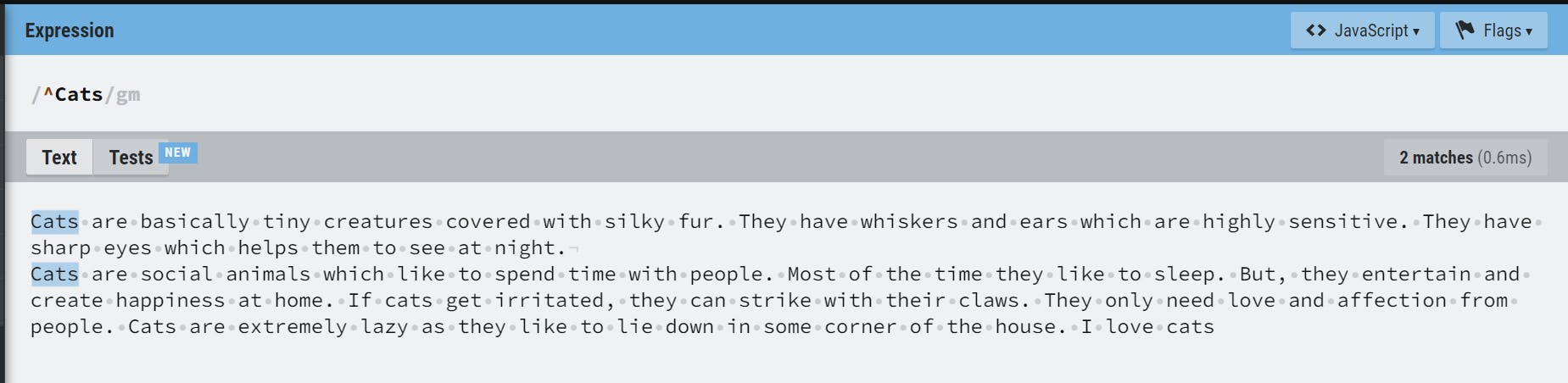
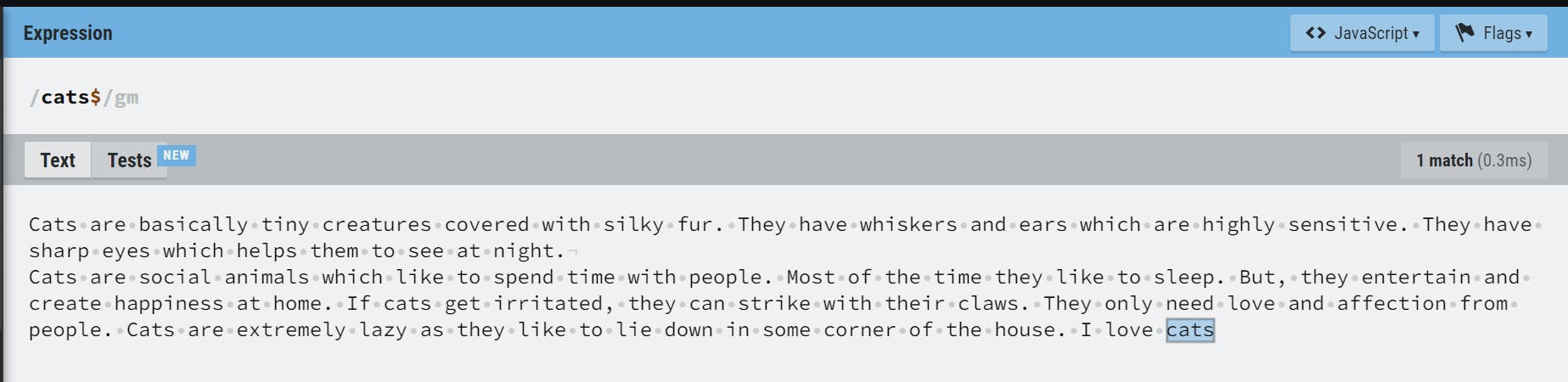
^ matches the beginning of the string or the beginning of a line if the multiline flag(m) is enabled.
$ matches the end of the string or the end of a line if the multiline flag(m) is enabled. These match a position, not a character.
Quantifiers(+, *, ?, {})
+ matches 1 or more of the preceding token. * matches 0 or more of the preceding token. {} matches the specified quantity of the previous token. {1,3} will match 1 to 3. {3} will match exactly 3. {3,} will match 3 or more.
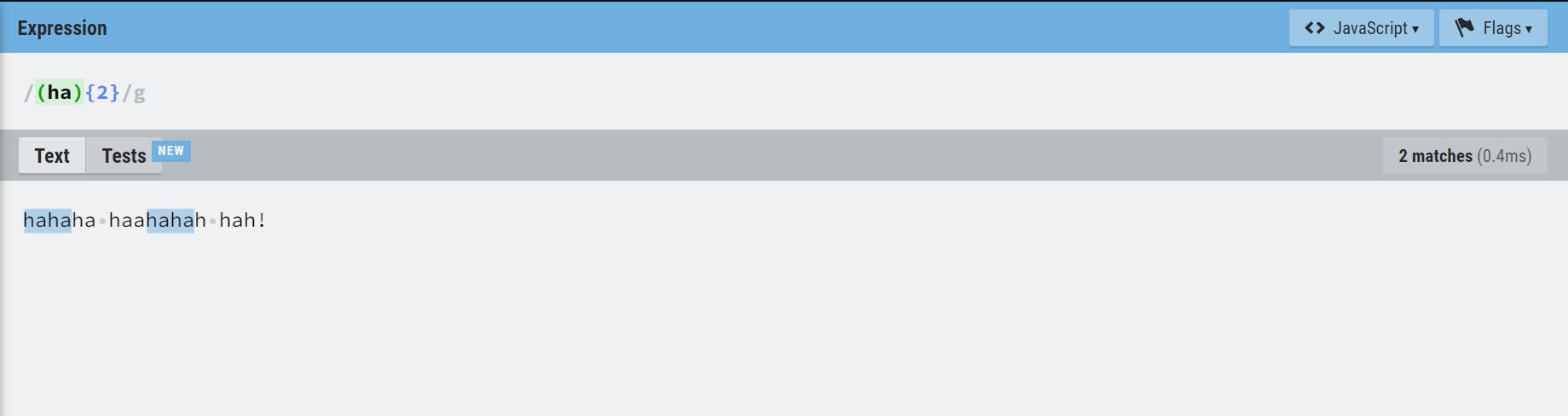
Groups ( () )
It groups multiple tokens together and creates a capture group for extracting a substring or using a backreference. In below example, /(ha){2}/ will look for exactly 2 has.
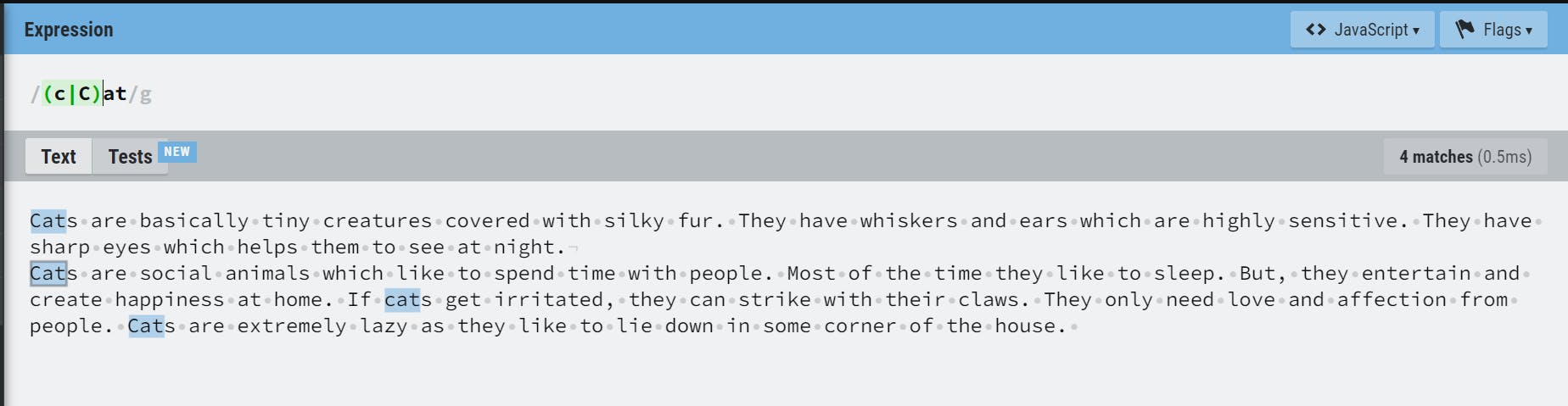
Alternation( | )
It acts as a OR operator and matches the expression before or after |. In this example, /(c|C)at/ will look for pattern Cat or cat.
Character classes
\wmatches any word character (alphanumeric & underscore) and is equivalent to[A-Za-z0-9_]\dmatches any digit character (0-9) and is equivalent to[0-9]\smatches any whitespace character(spaces, tabs, line breaks)\W,\D,\Smatch any character that is not a word, digit or a whitespace respectively.
So these are the most commonly used regular expressions to form different patterns. Look aheads((?=)) and look behinds((?<=)) can also be used to form complex regular expressions.
Example - validating phone number
Let's take an example to validate Indian mobile phone numbers. As per Wikipedia,
In India, mobile numbers (including pagers) on GSM, WCDMA and LTE networks start with either 9, 8, 7 or 6. All mobile phone numbers are 10 digits long. The way to split the numbers is defined in the National Numbering Plan as XXXXX-NNNNN.
So, we'll be validating for a 10 digit number starting from 9, 8, 7 or 6. To increase the complexity we'll also be checking for the prefix +91.
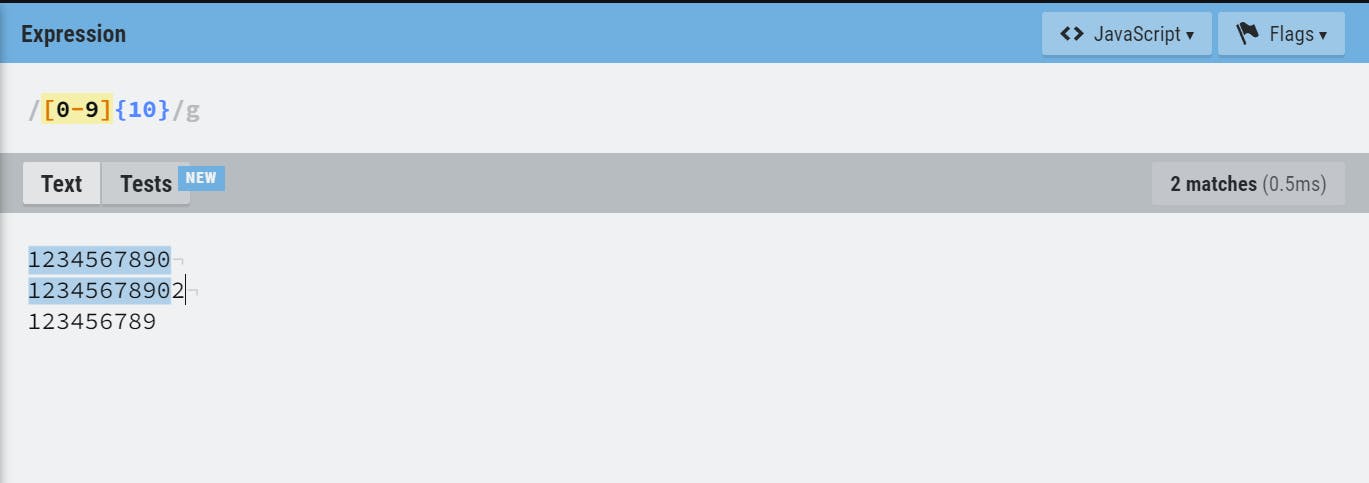
- Step 1: Checking for 10 digit Number
- Step 2: Check if the first digit is 9, 8, 7 or 6

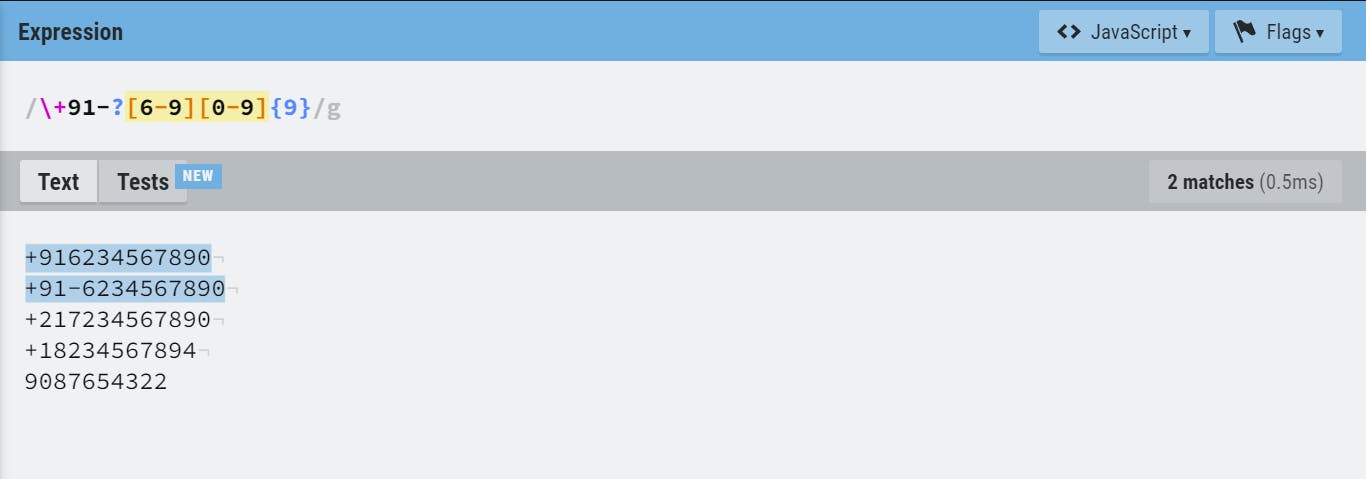
- Step 3: Checking for prefix +91

- Step 4: Additionally we can also allow numbers in the format +91-XXXXXNNNNN
Voila! We just wrote our own regex for validating Indian mobile numbers.
Cheatsheet
| Character classes | |
. | any character except newline |
\w\d\s | word, digit, whitespace |
\W\D\S | not word, digit, whitespace |
[abc] | any of a, b, or c |
[^abc] | not a, b, or c |
[a-g] | character between a & g |
| Anchors | |
^abc$ | start / end of the string |
\b\B | word, not-word boundary |
| Escaped characters | |
\.\*\\ | escaped special characters |
\t\n\r | tab, linefeed, carriage return |
| Groups & Lookaround | |
(abc) | capture group |
\1 | backreference to group #1 |
(?:abc) | non-capturing group |
(?=abc) | positive lookahead |
(?!abc) | negative lookahead |
| Quantifiers & Alternation | |
a*a+a? | 0 or more, 1 or more, 0 or 1 |
a{5}a{2,} | exactly five, two or more |
a{1,3} | between one & three |
a+?a{2,}? | match as few as possible |
ab | cd | match ab or cd |
Reference: regexr.com
Conclusion
I hope by now, you'll be having a basic idea of what regex is and how it can be written. Summarizing the key points of the blog:
- Regex is used for pattern matching.
- It is not restricted to any programming language
- You can refer to the above cheatsheet for the basic regular expressions.
- Regex is all about a set of special characters having special meaning.